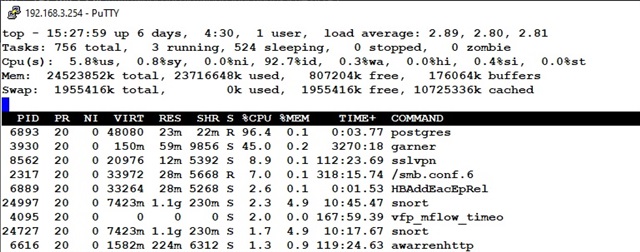
We have an XG 550 and from the beginning the web interface has been sluggish. It has gotten worse and now sometimes moving between windows takes 30 seconds or more depending on what we are doing. We just get the spinning wheel most of the time. Memory/CPU utilization aren't very high at all (memory is less than 60%). The main "control center" screen sometimes takes over a minute to fully load everything just so we can see bandwidth usage. Is there any trick to speeding this up to a workable level?
Edited TAGs
[edited by: emmosophos at 6:49 PM (GMT -7) on 7 Jun 2021]