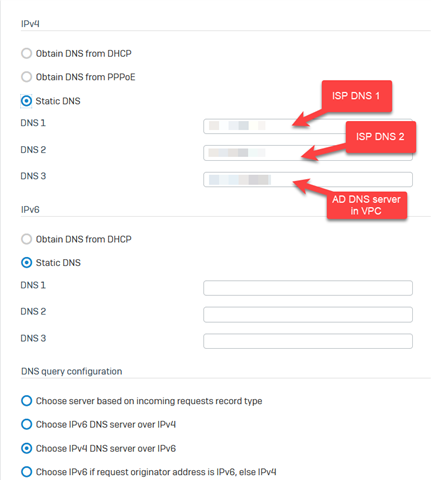
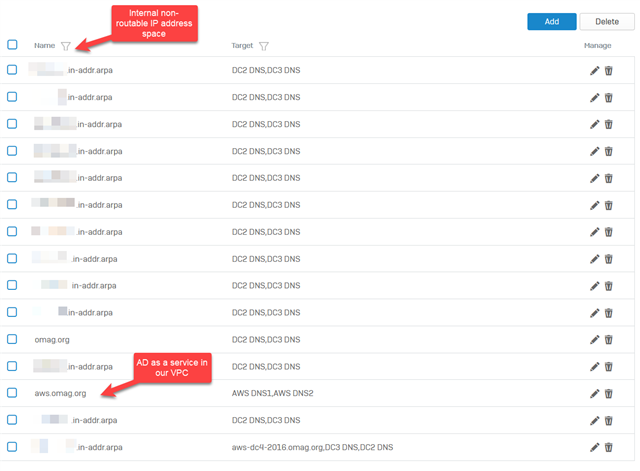
Running XG 18.0 MR5-Build586 on a pair of SG230's in HA (Active-Passive). We use the XG as a local cache and DNS relay, since we rely on AD DNS hosted in our AWS Virtual Private Cloud. We have DNS request routing setup so that only internal domains are going through the tunnel to the internal AD DNS servers, the rest should be our ISP's DNS. The firewall, as the closest to all of our endpoints, should be
Most recently, we discovered that we were having problems with random CPU spikes in a variety of processes (notably awarrenhttp, httpd, dnscache, and even garner) that would actually cause major network problems and inability to access the. As of today, we shut off firewall-acceleration. While we've only been monitoring for a couple of hours, our SG230's running XG 18.x do seem a lot happier, so I can recommend that to others having trouble.
However, a remaining problem, and one that has been a constant thorn in our side since migrating to XG 18.0 from UTM 9.x, is the DNS problem. We seem to have isolated this as its own separate issue and may explain a variety of threads of people complaining about poor DNS performance on XG 18. Here are our symptoms:
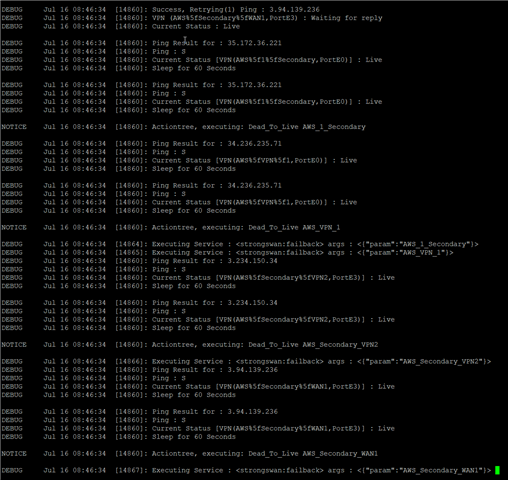
Every couple of minutes, we'll notice DNS resolution tanks. This is easiest to replicate by simply opening up CMD in Windows and running nslookup, then continually looking up various domains. After a minute or two, you'll hit a request and get nothing but timeouts on this latest lookup. Try again (which ends up being about 10 seconds later), and the request goes through and is, for the most part, nice and fast.
During this period, watching the top command on the XG indicates that the dnscache's CPU is spiking and consuming all available resources on 1 of the CPUs.
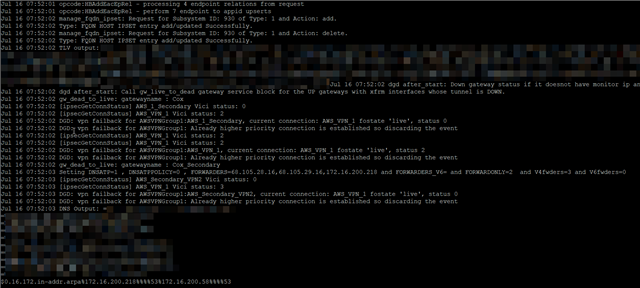
Also, during these periods, the {dnscache} dnsd process appears to be restarting. I've never seen this process last longer than about 2 minutes or consume more than about 20 seconds of CPU time before restarting.
The big problem is that dnscache itself doesn't have its own log file. dnsgrabber.log appears to be unhelpful, and simply refers you to the FQDND process. fqdnd.log, if you watch it for a couple of minutes, can show errors that correspond with the timing of the process restart, but it's only a symptom (for example, we see a lot of:

dnsd.log does show that it is frequently restarting:
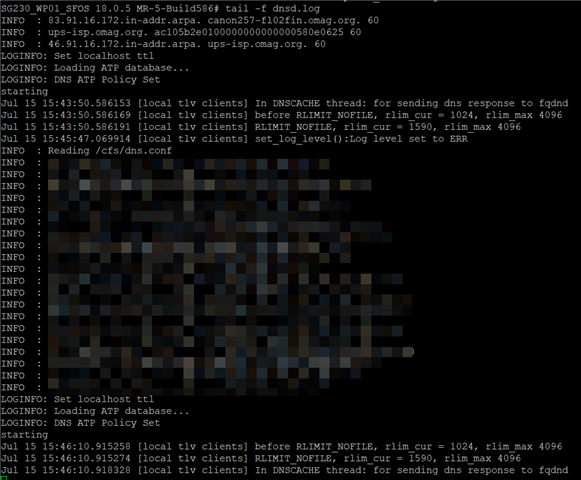
(Note the timestamps indicative of a restart every couple of minutes), and yes, this does correspond with the DNS resolution problems.
Finally, greping csc.log for "dnsd" gives us the following:
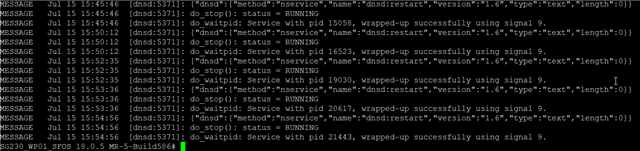
Which again, corresponds with the restarts.
Okay, so now that I know what is happening, I simply cannot find out WHY it is happening. We've had several tickets open with support on this and have gotten nowhere. These restarts are impacting network performance and causing loading problems for users. They also seem to be at the root cause of our disconnects to Sophos Central (since one of the dns queries it fails on is the Sophos Central Amazon server), as well as other issues.
Any takers on the issue?
This thread was automatically locked due to age.