

I have several 6.311 firewalls throughout our company. I would love to upgrade these firewalls to version 7. First, I wanted to test it on my home firewall to see if there were any issues. I installed the 7.006 ISO and started setting things up. After the initial configuration everything was working pretty well.
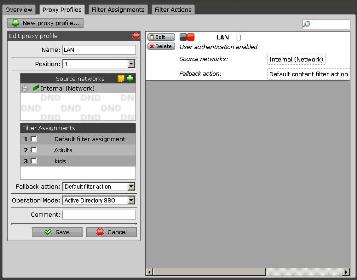
Shortly afterwards, I applied the updates all the way to version 7.009. After the updates, I went back through the configuration. This is when I realized that if I created a new (or edited an existing) http profile, I could no longer check the checkbox to assign a Filter Assignment to the profile. The up / down arrows are also missing. When I click on the checkbox for any of the filter assignments on this screen, it simply moves the filter assignment to the top of the list, but never puts a check mark in the checkbox. As a result of not being able to check the checkbox, the http profile will not enable in the system.
I have opened a support case with Astaro; however, since this is a home use license (my testing firewall), they will not support this issue. They did recommend that I ensure that the page is not being cached by emptying my history. I have deleted the history, cookies, and temporary internet files, closed the browser and went back into the web admin. The problem is still there.
Has anyone else ran into this issue? I cannot afford to upgrade all of our firewalls to version 7 with this issue still happening. Please see the attached screen shot of this issue.
This thread was automatically locked due to age.



{kind=link}