

Hi,
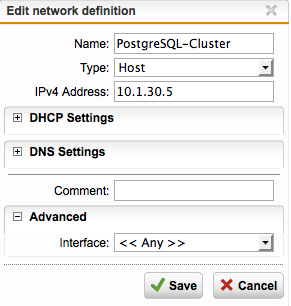
today i wanted to modify our backup solution for our Postgres-Cluster (Hot-Standby-Master-Cluster) which uses a virtual ip that is managed by pacemaker and assigned to either of those two servers interfaces.
On the other side i have the firewall which allows connections to PG (tcp/5432) and this virtual ip but everytime i try to connect, the firewall drops the packages. when i change the virtual ip to the normal ip of the master it works.
Another point is, that the connections come from a site-2-site IPSec VPN from the Office but its allowed on all gateways and only the firewall directly before this virtual ip drops the connection but allows it when using the normal interface IP
Can someone help me find the issue here?
We are using the UTM 9.1
This thread was automatically locked due to age.


{kind=link}