

Hello, I have 2 ASG 320 in HA cluster configuration and sometimes happen a strange problem:
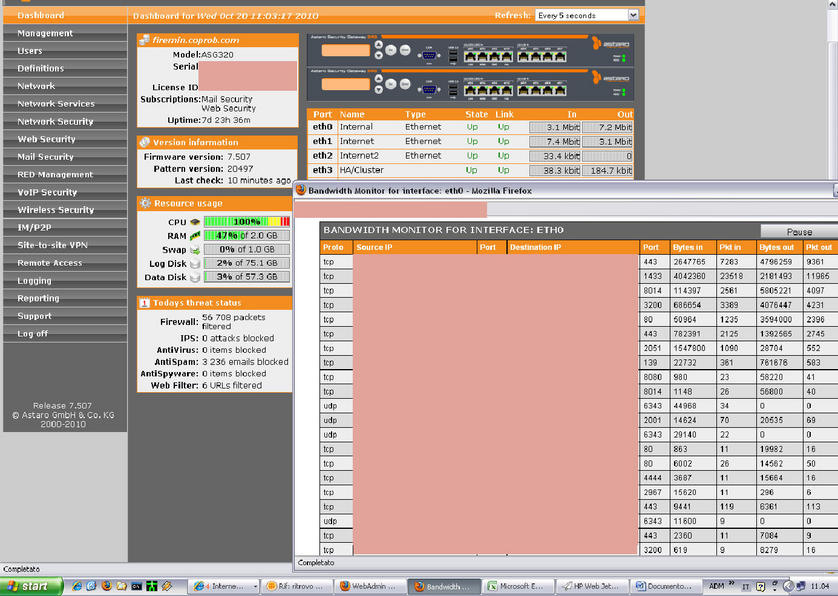
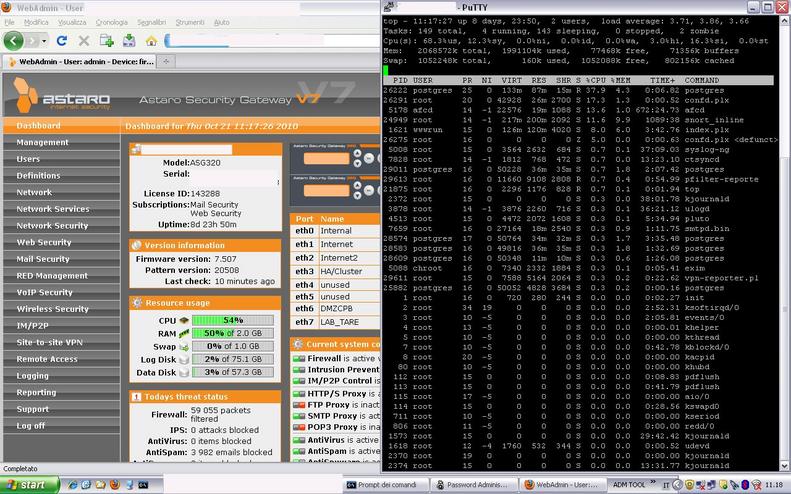
The primary node use high CPU ( 100% ) for 8-10 min; all performance degrade so VPN , incoming connections, and occasionally webadmin authentications fails.
I have identified some HA Sync daemon restart in those case
"HA confd sync daemon not running - restarted" and also "HA ctsync daemon not running - restarted".
Both ASG were restarted but problem persist; any idea ?
ASG version 7.507, pattern 20497
high cpu load was xpecially identifyed on the slave node, I suspect problem syncronization when changing role from master to slave
2010:10:20-10:56:27 firemin-2 kernel: nf_log_packet: can't log since no backend logging module loaded in! Please either load one, or disable logging explicitly
2010:10:20-10:56:28 firemin-2 kernel: asg_cluster: set master_id to 1
2010:10:20-10:56:49 firemin-2 kernel: nf_log_packet: can't log since no backend logging module loaded in! Please either load one, or disable logging explicitly
In my opinion when a high in/out going connection was detected and cpu load >80% cluster fail to check heartbeats and try to switch node but fail during datafile syncronizations.
look attached log :
This thread was automatically locked due to age.



{kind=link}
{kind=link}