

Hello,
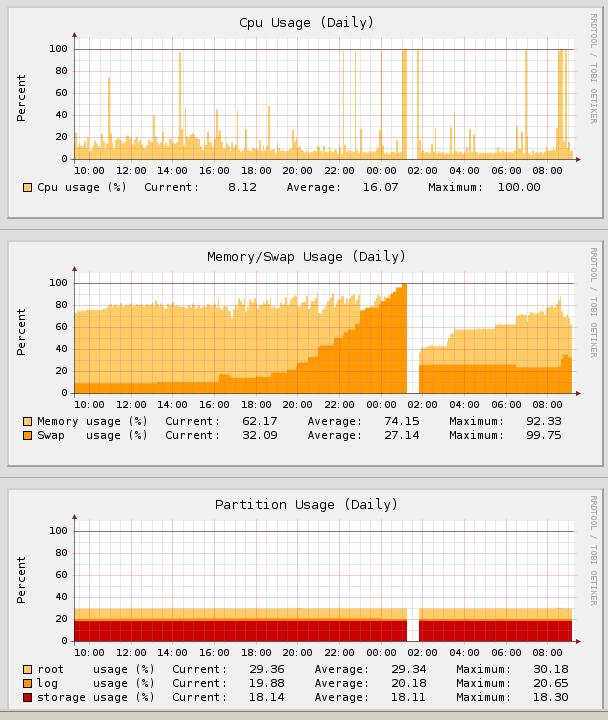
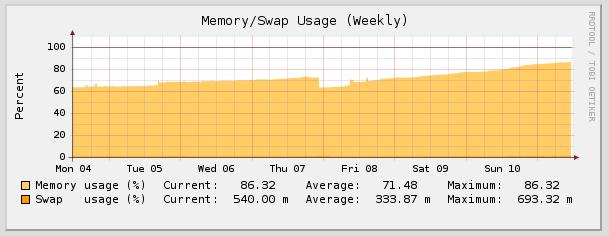
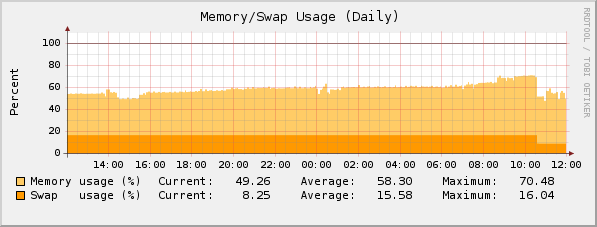
yesterday all the gateways I'm administering started to show the very same problem. Approximately starting at 18:00 CET the memory usage started to go up and swap usage started to grow until it reached 100% and the gateway just died...
Anyone else seeing this? All gateways I have administrative access to are having the same problem (about 10 boxes, different configs and license states).
Something stinks here and I really need this resolved ASAP because it brings down even HA configs... [:(]
This thread was automatically locked due to age.






{kind=link}
{kind=link}
{kind=link}