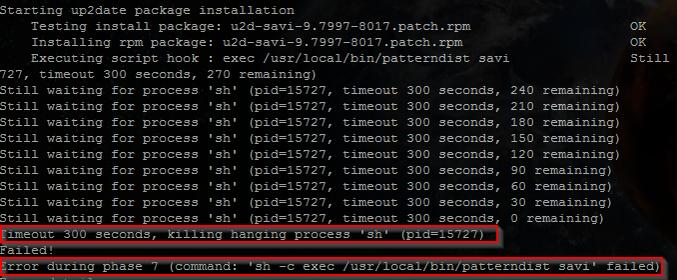
Hi,
I have a number of UTM 120s deployed for different clients. Several of these clients are now complaining that they occasionally lose Internet connectivity for periods of 30 seconds to a minute. VoIP call quality also decreases during this time.
I've verified that every time, I'm seeing CPU spikes to 80-100% on the UTMs.
If I turn off Web Filtering, the problem goes away, but I don't like leaving that off.
I've rebooted the UTMs, updated them, checked settings for anything I can limit, and nothing seems to be working.
Do I have bad UTMs? Is there a recent firmware update that increased resource usage? Are they just overloaded?
I'd appreciate any help. I'm stuck.
Thanks!
This thread was automatically locked due to age.