

Hi all,
I recently had a situation where all L2L VPN tunnels on the UTM went down and stayed offline despite the device appearing responsive. I corrected the issue by simply toggling each tunnel on/off. On examination of the logs, I found that the system had run out of memory and many services were killed and restarted. At this time, many processes were restarted but for purposes of this post the important ones were dhclient and pluto. It looks like the VPN subsystem came back online before dhclient was able to get an IP for the interface. As a result the vpn subsystem failed to come online with a line like the following recorded for each tunnel:
2015:04:10-04:57:15 Prod-RAVPN01 pluto[17384]: "S_REF_removed_0": we have no ipsecN interface for either end of this connection
2 seconds after this message dhclient got its IP, but no retry occurred. Manual fix was to toggle each tunnel on/off and all was happy.
So two issues:
- It would be great if that race condition could be solved. My understanding is that this is a known issue.
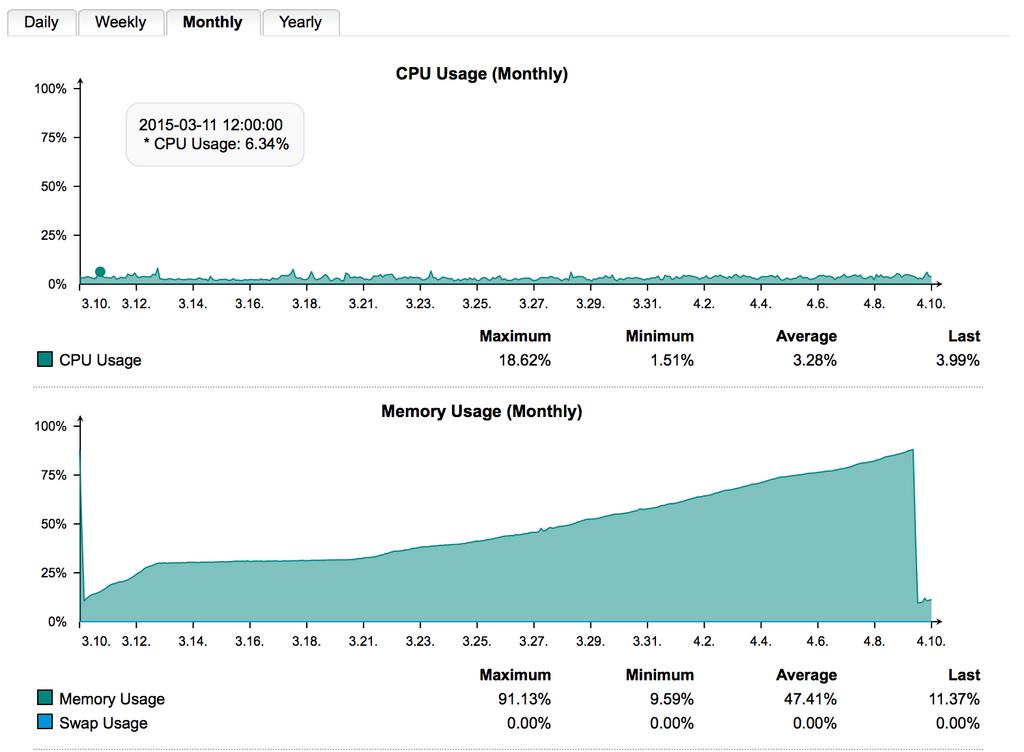
- More important, it seems to me that a memory leak is what caused the crash. The attachment seems like strong proof of a leak. This device provides RA and L2L VPN services and basic NAT/firewall type functionality. We don't use Web, Email, Endpoint, Wireless, or Web Protection features at all.
Not sure if it matters but this instance is an AWS virtual appliance version of the UTM. I looked at the up2date patches pending and none of the bugfixes seem related to a memory leak. I can probably find out what process is leaking once some time goes by, but not sure what if anything I can do to fix it aside from restarting whatever process is leaking.
This thread was automatically locked due to age.

{kind=link}