

So, I've been playing with the ASG for some time now in my lab at home, and I really wanted to show it to some one. I jump online, VPN'd in and showed them how easy it is. After work we headed over to the house to see it first hand and when we arrive I find the gateway just killing itself at 100% CPU usage. Nothing was possible, IE web browsing, or even logging in to the system... (yes I did get in at one point see pictures)
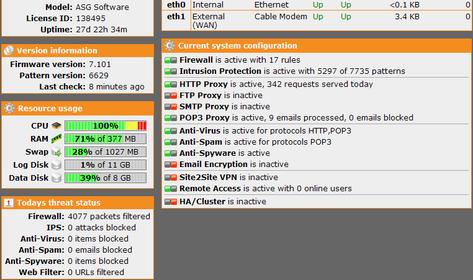
Image asg100.jpg shows the system running at 100% CPU even though it has worked flawless for 25+ days. CPU never really peeked over 40% for any reason during that time.
Image asgday.jpg shows a snapshot of the physical servers CPU usage for the day.
Image asgtop.jpg shows a snapshot of a ssh session running the "top" command.
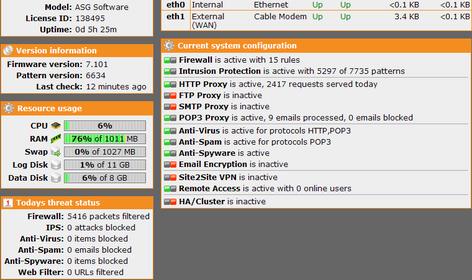
Image asg100-r.jpg is a picture of how the CPU% continued to peek after rebooting many times, even after adding a second CPU (1 ghz p3x2) and adding 3 times the amount of ram. It didn't slow down for hours.
No users at all using the system for anything. But still the httpproxy is using up all the proc. As a test I unplugged the larger 48 port switch and plugged in a four port which removed all computers in my lab network and allowed me to connect a single computer.
Needless to say the person I was trying to show and suggest Astaro to was completely unimpressed.
What I can't understand for the life of me is I've been using the ASG flawlessly for a month. Thing has been like a damn top. So what happened today?
This thread was automatically locked due to age.











{kind=link}
{kind=link}