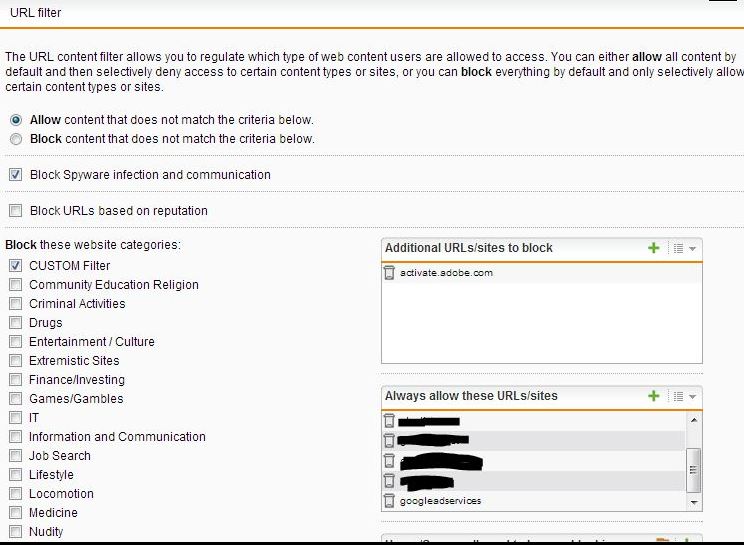
Hi, the newer style of url filtering exceptions is nice and gives more control but all my previous settings were lost when I installed my backup. Is this intentional?
Screenshots of previous settings and current settings.
Further comments and screen shots for this.
Hi All
I just noticed that my Blocked sites list was Also not imported.
I than clicked on "edit" "Any domain expression" line that was inserted and found that all my exclusions where listed as regular expressions and not as Domain names, this is also the case for the "Allow sites" Field area.
So the information has been imported just not into the correct areas.
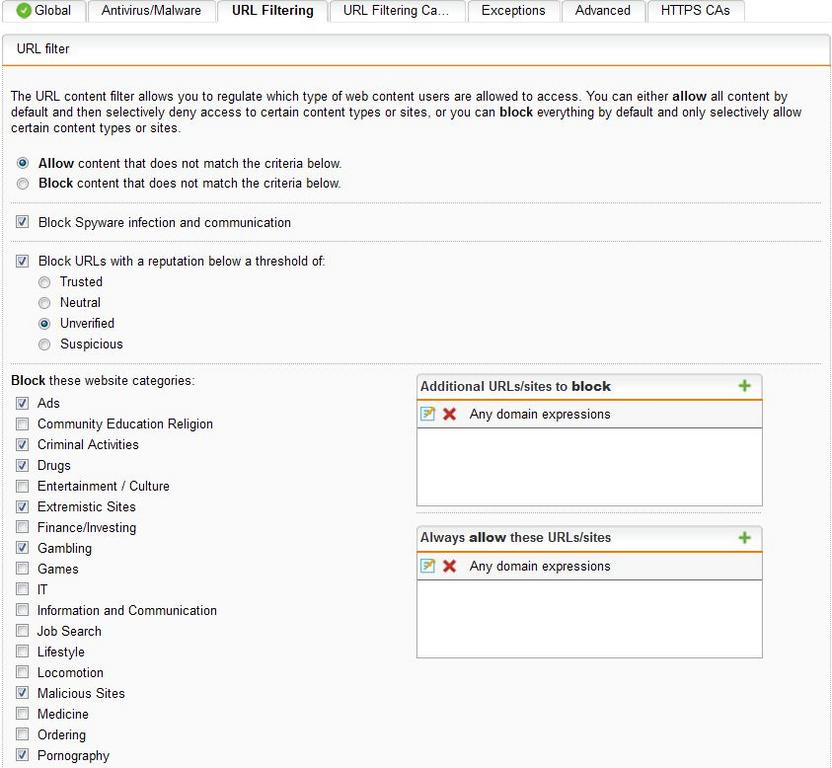
See pics
The migration of "old" regular expressions to the new scheme is intentionally done like this. Previously every regular expressions has been tested against every request. This has changed in 9.1. First of all a string-comparison is done, based on the domainnames. If there is a hit the request-url is tested against every regular expression.
Previously there was only the option to match any expression on any request which is in fact less efficient.
After the migration to utm9.1 it should exactly look as seen in your pictures and behave as in the past.
You can of cause improve performance if those regular expression which should match a whole domain (FQDN) are moved to a new rule. The new rule should contain only a list of domainnames and __no__ regular expression.
This movement is not done automatically since this decision is non-trivial.
corner cases: - having no domains in the list means "regular expressions" are matched against any request. - having no "regular expressions" in the list means that the whole domain is matched.
In this migration rule checking how hard would it be to move the domain specific expressions into the proper location?
This will reduce the double handling of Rules for the "End User" 1. As they wonder where they Domain rules went. 2. Then moving them from "Expressions" to "Domain" Rules.
That is what they are intended for, this makes management easier in the long run.
Moving the domain specific expressions to their "proper locations" would change the behavior.
For example in 9.0 the expression "google.com" would match "www.secretproxy.com/GoToSite/www.google.com"
If you want to maintain this functionality the expression google.com must be migrated automatically to the regular expressions. If the user wants the improved performance of only checking the domain name (not entire url) they have to move it themselves.
The alternative (automatically recognizing that "google.com" is a domain name and moving it to the domain check) would change the behavior.
Thank you Michael for your explanation. That makes a lot of sense. However I think there will be some initial confusion for everyone that upgrades their box. The feature is great moving forward but the initial migration is less than desirable specially for people with large lists. But I see the problem... without knowing the intent of the admin, its hard to know if they are blocking a specific domain or any domain with a certain word.
FWIW, in your google.com example, I have always used that as a way to block only google.com
Like wise I agree with Bob and I don't think repeating the same thing changes this fact.
Could I suggest a change note "Feature Note" whatever you call it. That when v9.1 is released that this function is published. So That people will understand this new change/feature.
I believe this is required because on migration the existing data is going to be changed (yes in only a small way). Being informed the User/Admin has the power to do something about it, investigate this function and understand the change or ignore it. It is then in their hands as they have been informed.






{kind=link}
{kind=link}