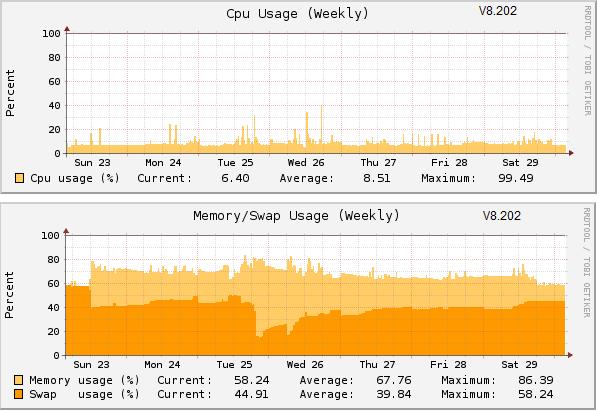
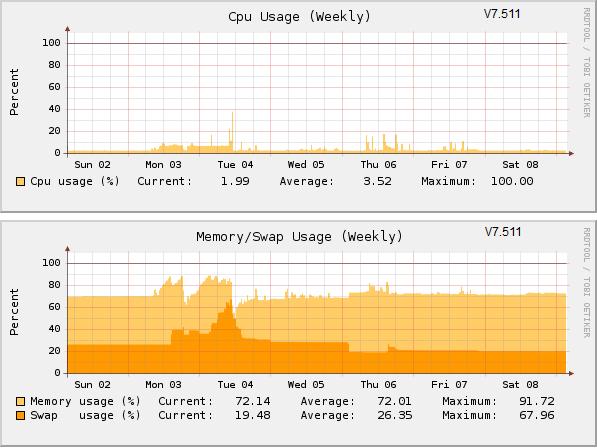
12:28 Middleware not running - restarted
12:28 IM/P2P classifier not running - restarted
12:30 Dhcpd not running - restarted
01:04 Spam filter cannot query database servers
01:29 Dhcpd not running - restarted
01:31 Middleware not running - restarted
[...]
02:39 Service Monitor not running - restarted
[...]
04:22 ACC device agent not running - restarted
[...]
08:41 IM/P2P classifier not running - restarted
After that my laptop could not connect via any VPN, nor could I get answers to ping. The same was true with my iPhone via the cellular network.
Cheers - Bob