

Hi,
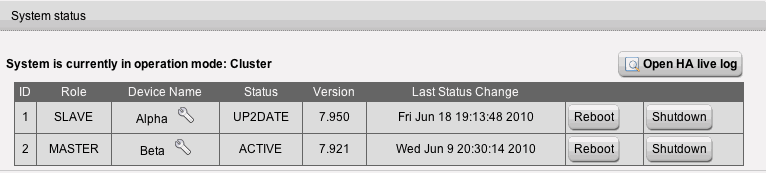
The cluster downloaded the updates and I tried to kick off the automatic update process. Slave node received the update first (as usual), it appeared to apply OK, automatically rebooted but never left the up2date process despite the log file showing that a successful sync had occurred. Left for about 8 hours and still no change, rebooted slave node, came back but master continued to report it was in the up2date mode.
Cheers,
Darren

{kind=link}