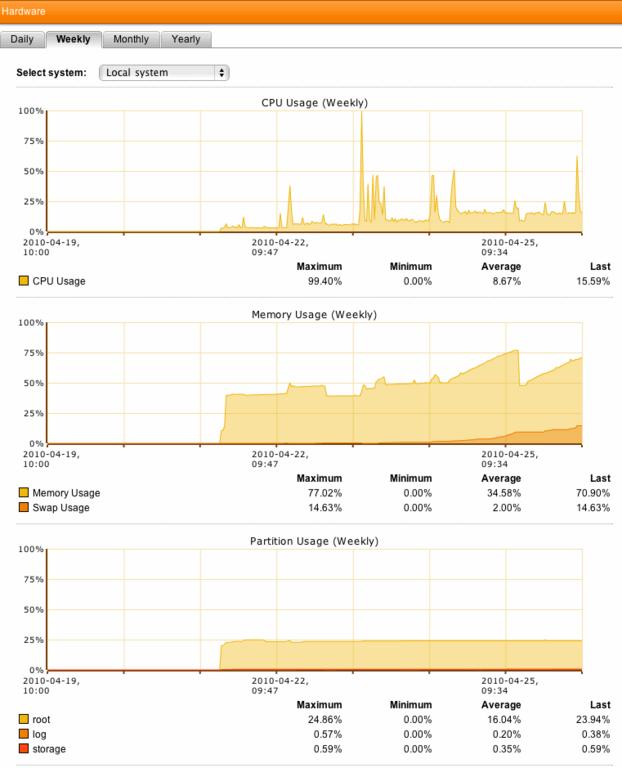
Since moving the platform to an active/active cluster config I'm noticing an ongoing daily increase in CPU utilisation and an interesting memory utilisation pattern.
Interesting update - the master server within the cluster just fell over and rebooted.
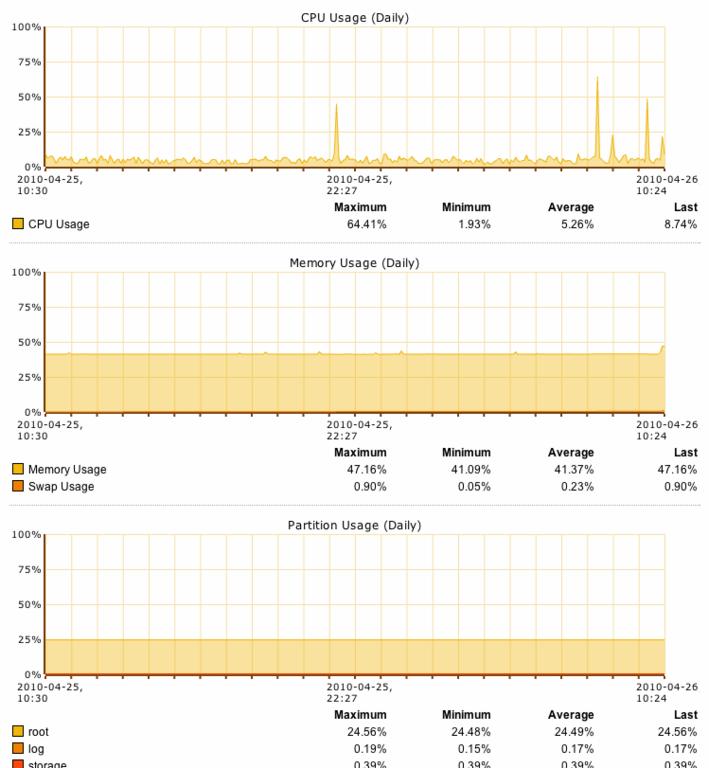
Due to the bug in reporting (master and nodes all show the same performance stats) I now can see the utilisation stats from what was the worker node. Looks near 'normal' compared to the master.
Interesting update - the master server within the cluster just fell over and rebooted.
Due to the bug in reporting (master and nodes all show the same performance stats) I now can see the utilisation stats from what was the worker node. Looks near 'normal' compared to the master.



{kind=link}
{kind=link}