

Hi. My battle.net client (Blizzard games like WoW, StarCraft, etc...) cannot update if HTTP scanning is turned on. It works if I disable HTTP scanning in the web filter. I do not have HTTPS scanning turned on. I have tried bypassing these sites from getting scanned and it still does not work. Here's a great list of regex exceptions from UTM 9 that don't seem to work with XG Firewall.
https://community.sophos.com/products/unified-threat-management/f/55/p/45070/161552
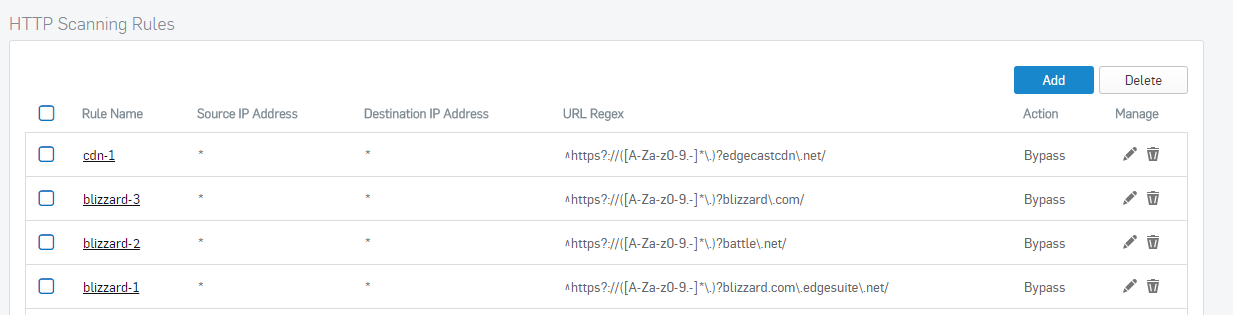
This thread was automatically locked due to age.

