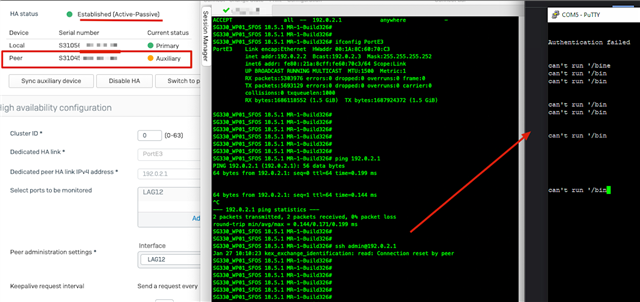
our customer has a HA Cluster containing 2x SG330 Rev 1 running SFOS 18.5.1 MR-1-Build326. within the same week the primary devices failed and did not failover to the auxiliary. It was necessary to manual power off the primary to trigger a failover to the aux. after the primary power cycled it switched back to primary, since failback 2 primary is checked.
in both cases, there is not much i can find in the logs.
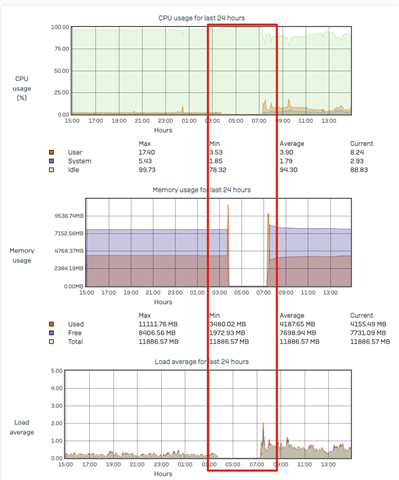
From the primary devices it looks like it "freezed" to death. LED display was unresponsive at that time.
From the aux devices it looks like it did no noticed the primray died.
the few logs i can see are after the reload on of the primary. crash happend around 03:00 and power cycle around 07:00, there are no logs in between.
Primary device:
1974 2022-01-20 07:08:15.204 GMTLOG: database system was interrupted; last known up at 2022-01-20 02:09:39 GMT
1974 2022-01-20 07:08:19.441 GMTLOG: database system was not properly shut down; automatic recovery in progress
this messaged keeps spamming the syslog:
Jan 20 02:57:04 localhost kernel: [10488717.715382] netlink: 153776 bytes leftover after parsing attributes in process `ipsetelite'.
Jan 20 03:00:04 localhost kernel: [10488897.692808] netlink: 153776 bytes leftover after parsing attributes in process `ipsetelite'.
Jan 20 03:03:04 localhost kernel: [10489077.710459] netlink: 153776 bytes leftover after parsing attributes in process `ipsetelite'.
Jan 20 03:06:04 localhost kernel: [10489257.660675] netlink: 153776 bytes leftover after parsing attributes in process `ipsetelite'.
Jan 20 03:09:03 localhost kernel: [10489437.533547] netlink: 153776 bytes leftover after parsing attributes in process `ipsetelite'.
the network logs after the reload indicate the both devices were active at one point..
i assume the applianced played pingpong a couple of time untill the cluster was backup again.
Jan 24 07:15:34: %IP-4-DUPADDR: Duplicate address 192.168.25.1 on Vlan25, sourced by 00e0.2011.0976
Jan 24 07:15:34: %SW_MATM-4-MACFLAP_NOTIF: Host 00e0.2011.0976 in vlan 309 is flapping between port Po44 and port Po45
Jan 24 07:15:35: %SW_MATM-4-MACFLAP_NOTIF: Host 00e0.2011.0976 in vlan 310 is flapping between port Po44 and port Po45
Jan 24 07:15:35: %SW_MATM-4-MACFLAP_NOTIF: Host 00e0.2011.0976 in vlan 75 is flapping between port Po44 and port Po45
Jan 24 07:15:40: %LINEPROTO-5-UPDOWN: Line protocol on Interface TwentyFiveGigE2/0/45, changed state to down
Jan 24 07:15:40: %LINEPROTO-5-UPDOWN: Line protocol on Interface TwentyFiveGigE1/0/45, changed state to down
Jan 24 07:15:40: %LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel45, changed state to down
Jan 24 07:15:41: %LINK-3-UPDOWN: Interface TwentyFiveGigE2/0/45, changed state to down
Jan 24 07:15:41: %LINK-3-UPDOWN: Interface Port-channel45, changed state to down
Jan 24 07:15:41: %LINK-3-UPDOWN: Interface TwentyFiveGigE1/0/45, changed state to down
Jan 24 07:17:27: %LINK-3-UPDOWN: Interface TwentyFiveGigE1/0/45, changed state to up
Jan 24 07:17:28: %LINK-3-UPDOWN: Interface TwentyFiveGigE2/0/45, changed state to up
Jan 24 07:17:36: %ETC-5-L3DONTBNDL2: Twe1/0/45 suspended: LACP currently not enabled on the remote port.
Jan 24 07:17:37: %ETC-5-L3DONTBNDL2: Twe2/0/45 suspended: LACP currently not enabled on the remote port.
Jan 24 07:18:01: %ETC-5-L3DONTBNDL2: Twe2/0/45 suspended: LACP currently not enabled on the remote port.
Jan 24 07:18:02: %ETC-5-L3DONTBNDL2: Twe1/0/45 suspended: LACP currently not enabled on the remote port.
Jan 24 07:19:50: %LINEPROTO-5-UPDOWN: Line protocol on Interface TwentyFiveGigE1/0/45, changed state to up
Jan 24 07:19:50: %LINEPROTO-5-UPDOWN: Line protocol on Interface TwentyFiveGigE2/0/45, changed state to up
Jan 24 07:19:51: %LINK-3-UPDOWN: Interface Port-channel45, changed state to up
Jan 24 07:19:52: %LINEPROTO-5-UPDOWN: Line protocol on Interface Port-channel45, changed state to up
Jan 24 07:20:18: %SW_MATM-4-MACFLAP_NOTIF: Host 00e0.2011.0976 in vlan 309 is flapping between port Po45 and port Po44
Jan 24 07:20:20: %SW_MATM-4-MACFLAP_NOTIF: Host 00e0.2011.0976 in vlan 310 is flapping between port Po44 and port Po45
Jan 24 07:20:21: %SW_MATM-4-MACFLAP_NOTIF: Host 00e0.2011.0976 in vlan 309 is flapping between port Po44 and port Po45
Jan 24 07:20:23: %SW_MATM-4-MACFLAP_NOTIF: Host 00e0.2011.0976 in vlan 310 is flapping between port Po45 and port Po44
Jan 24 07:20:24: %SW_MATM-4-MACFLAP_NOTIF: Host 00e0.2011.0976 in vlan 309 is flapping between port Po45 and port Po44
Jan 24 07:20:36: %SW_MATM-4-MACFLAP_NOTIF: Host 00e0.2011.0976 in vlan 80 is flapping between port Po45 and port Po44
Jan 24 07:20:38: %SW_MATM-4-MACFLAP_NOTIF: Host 00e0.2011.0976 in vlan 310 is flapping between port Po45 and port Po44
Jan 24 07:20:39: %SW_MATM-4-MACFLAP_NOTIF: Host 00e0.2011.0976 in vlan 309 is flapping between port Po45 and port Po44
HA Link is done by a Cable back2back. Ports look fine.
SG330_WP01_SFOS 18.5.1 MR-1-Build326# ifconfig PortE3
PortE3 Link encap:Ethernet HWaddr 00:1A:8C:5F:E2:47
inet addr:192.0.2.1 Bcast:192.0.2.3 Mask:255.255.255.252
inet6 addr: fe80::21a:8cff:fe5f:e247/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:643351 errors:0 dropped:0 overruns:0 frame:0
TX packets:1032066 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:492887169 (470.0 MiB) TX bytes:284445208 (271.2 MiB)
PortE3 Link encap:Ethernet HWaddr 00:1A:8C:60:70:C3
inet addr:192.0.2.2 Bcast:192.0.2.3 Mask:255.255.255.252
inet6 addr: fe80::21a:8cff:fe60:70c3/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:945885 errors:0 dropped:0 overruns:0 frame:0
TX packets:378813 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:278501212 (265.5 MiB) TX bytes:120476213 (114.8 MiB)
are there any known issues?
someone else exprerienced cluster hangs?
(this is the 4th or 5th time for this customer.. both appliances were replaced since their initial installation due to disk failure.. )
This thread was automatically locked due to age.