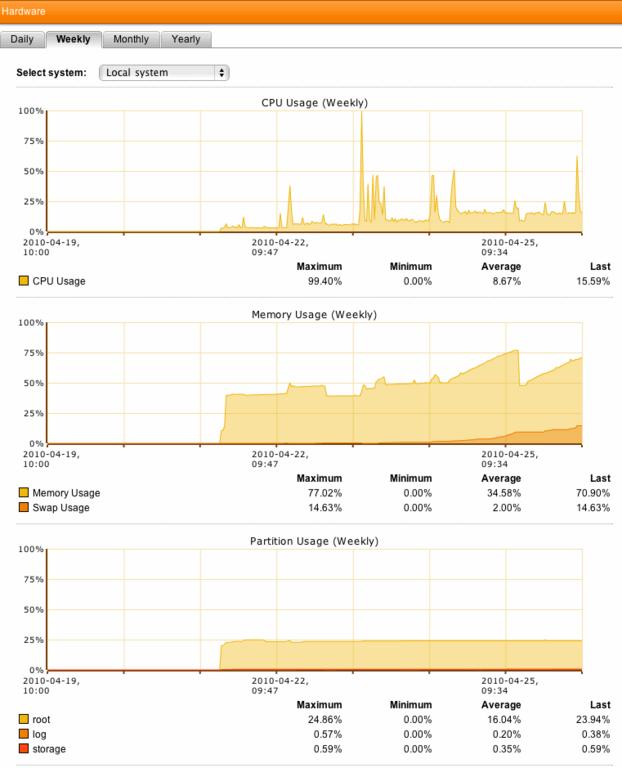
Since moving the platform to an active/active cluster config I'm noticing an ongoing daily increase in CPU utilisation and an interesting memory utilisation pattern.
Is there a way of 'toggling' between the master and slave nodes without having to go to the console itself (as both use the same IP address) ? i.e. a command via ssh?
Cluster has now been running for a few hours: memory and CPU utilisation on the master node has been slowly but constantly increasing and I've noticed these being reported in the kernel log: 1=master, 3=slave node.
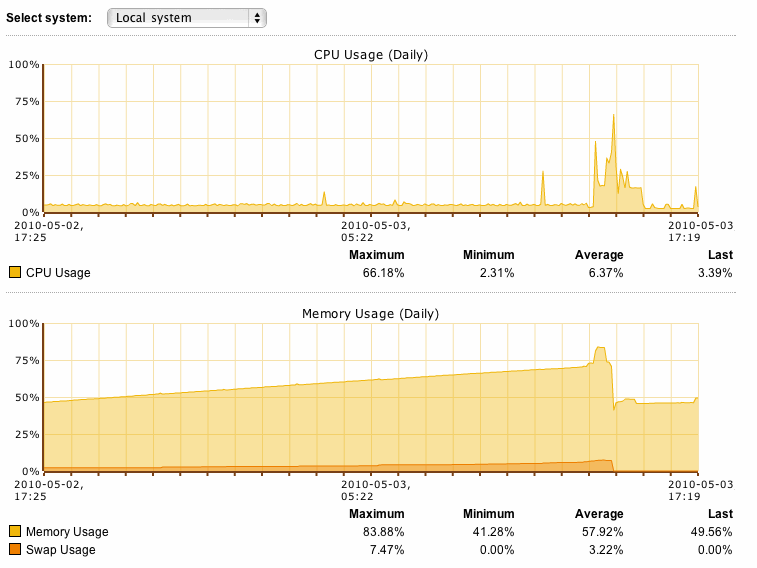
Looks like the memory consumption is still continuing. After applying the new files the system and rebooting the master node (1) dropped to 46.71% memory utilisation, currently sitting at 49.56% after 3 hours.
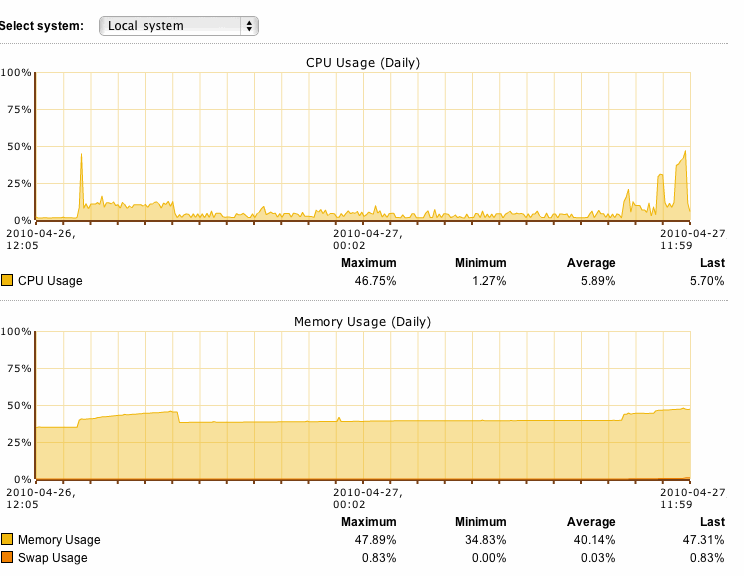
Since there has been no more web traffic running through the proxy for about 4 hours, memory utilisation has returned to "normal" - it seems to have been cleared at 19.00 BST. Earlier today I had several people running web traffic through it, during this time memory utilisation increased by 5% over the 60 minute test. CPU utilisation moved from 2% to around 24% with a peak at 66%.
I'm not about tomorrow (Tues) but will take more readings on Wednesday.



{kind=link}
{kind=link}
{kind=link}